Adding replication to the Key-Value Store
During the past few weeks I’ve built a basic key-value store that persists data to disk. It works, but only as a single node, so there is a fixed limit on the amount of data it can store, and the througput it can sustain.
We can make the store scale horizontally in two ways:
- Replication, which keeps additional copies of the data in other nodes, improving throughput.
- Sharding, which partitions the keys across different nodes, so that we can store more data.
In this post I’m going to tackle the first one, replication, refactoring the storage layer so that we can have as many replicas as we want serving reads. All the code is available in GitHub.
Why Replication?
Any modern database these days will keep an additional copy of the data on a different server. That has a couple of advantages:
If the original server dies, the other one can take its place and answer queries.
If you have the data in multiple servers, clients can call any of them, so now you have several times the original read throughput!
This also comes with downsides. If you have replicas, now the store is distributed, and that comes with a lot of added complexity and failure modes. You have to decide how to handle writes, and what happens when different nodes disagree about the current state of the system.
Alternatives
There are usually three approaches:
Single Leader replication: One leader is configured as the leader, and it’s the only one that can process writes. It then sends the data to the followers. Both leader and followers can process read operations.
Multi-leader replication: Same as above, but now you have more than one replica processing write operations. It’s usually done to replicate data across data centres. You can configure one leader per data centre, the leader will send updates to the local replicas, and then send it over the internet to the leader of the other data centre.
Leaderless replication: This is the other extreme, any node can accept write operations. This one requires consensus algorithms to decide what to do when two concurrent writes across different nodes try to write to the same key.
All of this is really well explained in the “Designing Data-Intensive Applications” book, by Martin Kleppmann, I really recommend it!.
Single Leader Replication
In my Key-Value store I’m implementing the “simplest” approach for now. Only one leader in the cluster, and it is pre-configured. What happens if the leader dies? Ideally we would implement a leader election algorithm to pick another one. For now my implementation just stops accepting writes.
Even if we only limit the system to have one writer, we still can have consistency problems. Since sending updates to the follower replicas takes time, they can fall behind. It’s possible for a client to write an update to a key, then try to read it from a different replica, and get the old value. Using this scheme the store can only be “eventually consistent”. A way to mitigate this issue is to call the leader to read data that we updated recently.
At the very least we will want to make sure that each client reads from the same replica to ensure that the data is internally consistent and doesn’t go back in time (you could get a value from an up to date replica, then read it again from a replica falling behind, and get an older value, not the one that was last written).
Implementation
Before writing this I took the chance to do some refactoring. I split the storage layer into disk & memory storage, with a store module to coordinate them. Then, adding a replication layer was easier.
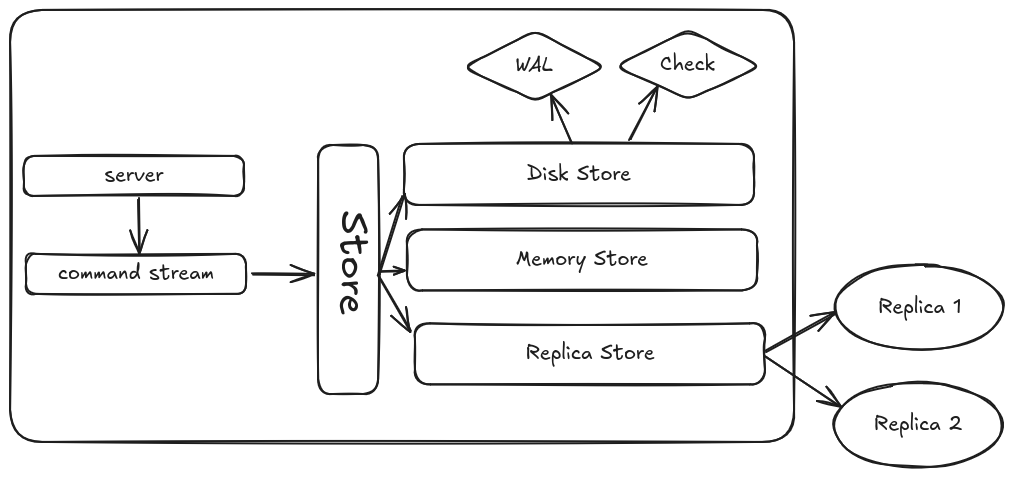
The Store coordinator
Now each server node can operate on two different modes, as a Leader, or a Follower. It also needs some configuration, so that it can find the replicas, and it also needs to know where to store the WAL, and the disk checkpoint (see previous post).
Also, update operations now need network access. This complicates a bit the signature of the function, since now we need to take the Eio Switch, and the network token.
open! Base
type t
type mode =
| Leader
| Follower
[@@deriving sexp]
type config = {
replica : Replica_store.replica_config;
disk : Disk_store.disk_config;
mode : mode;
}
[@@deriving sexp]
val make : config -> t
val update : t -> Model.update_op -> Eio.Switch.t ->
[> [> `Generic ] Eio.Net.ty ] Eio.Resource.t ->
unit Or_error.t
val get : t -> Model.Key.t -> Model.value option
val default_config : config
An update needs to:
- Store the update operation in the WAL
- If the node is the leader, it needs to propagate it to the replicas
- Store the date in memory
- Consider if a checkpoint is required
If any of this operations fails we return an error to the client. We
can model that with Or_error, using the bind (»=) operator (monads!).
let update store op sw net =
let open Or_error in
Disk_store.process store.disk op
>>= fun () -> match store.config.mode with
| Leader -> Replica_store.update store.repl op sw net
| Follower -> Ok ()
>>= fun () ->
Memory_store.update store.mem op;
Ok ()
>>= fun () ->
store.op_count <- store.op_count + 1;
(if store.op_count > 5 then
let () = store.op_count <- 0 in
Disk_store.checkpoint store.disk store.mem
else
Ok ())
Thanks to bind we can chain functions that return Or_error.t, and
as soon as one of them is an Error, the execution is aborted,
returning it. It saves us the time of having to check each result
individually.
The code above is trigering a checkpoint every 5 operations. Usually this value would be a lot higher, but I’m using a low number so that I can see it working.
Also, you may have noticed that there is nothing here keeping followers from accepting write operations! That’s correct, it’s in my TODO list. It should accept updates only from the accepted leader, and reject the rest.
The Replication layer
There isn’t much to it, just iterate over the replicas sending the updates. Ideally we could send the updates in parallel, and maybe stop waiting after n replicas acknowledge the change, but for now I’m keeping the code simple.
let update replica op sw net =
Or_error.try_with @@ fun () ->
List.iter replica.config.replicas ~f:(fun (ip, port) ->
let ipp = Unix.inet_addr_of_string ip in
let ipv4 = Eio_unix.Net.Ipaddr.of_unix ipp in
let addr = `Tcp (ipv4, port) in
let flow = Eio.Net.connect ~sw net addr in
let open Protocol in
let command = to_command op in
Eio.Buf_write.with_flow flow @@ fun to_server ->
send_commands [command] to_server
)
Next steps
Now we have a single-leader replication scheme for the key-value store that can scale its read throughput horizontally by adding more replicas, but there is still a lot to do:
- Ensure that the followers only accept updates from the leader.
- Benchmark replication latency, and improve performance.
- Implement a leader election algorithm, maybe Raft.
- Scale storage through sharding, partitioning keys across nodes.
What we have today is a basic skeleton that can be used to experiment with more complex algorithms. Things are getting interesting!
All the code is available here. If you came this far I would love to hear you comments and feedback. You can find me on X / Twitter!